A single agent that calls tools is sometimes called multi-agent by marketing teams. It is not. A real multi-agent system has two or more agents with separate prompts, separate tool sets, and a protocol for talking to each other. The pattern is powerful for a small number of tasks and wasteful for the rest. This post defines what multi-agent actually means, when to reach for it, the four patterns that have stabilised in 2026, and the failure modes that turn polished demos into production incidents.
The framing here is operational, not academic. Anthropic's engineering team published their research-agent architecture in 2025 and reported it used roughly fifteen times more tokens than a single Claude chat (How we built our multi-agent research system, retrieved 2026-05-09). That number sets the cost ceiling for multi-agent: it must justify a 15x bill or it should be a single agent.
What a multi-agent system is
A multi-agent system is two or more autonomous agents that coordinate to achieve a shared goal. Each agent has a role (researcher, planner, executor, critic), a prompt that defines that role, a tool catalogue scoped to the role, and memory that persists across the agent's own steps. The agents communicate either by passing messages directly to each other or by reading and writing to a shared workspace.
The defining property is that no single agent contains the whole loop. Goals, perception, planning, action, and learning (the five pieces covered in agentic AI without jargon) are distributed across the agents. One agent may handle planning; another perception; a third action. The orchestration layer holds the system together.
This is different from a single agent that calls multiple tools. The model that ships in most LangChain or LlamaIndex tutorials is a single agent with a tool catalogue: the LLM decides which tool to call, parses results, and continues the loop. There is one prompt, one memory, one decision-maker. That is not multi-agent. It is a tool-using single agent.
When to use it (and when not)
The honest answer is that most production agent tasks should not use multi-agent. Three signals justify the additional complexity:
- The task naturally splits into distinct roles with conflicting prompts. A researcher needs a curiosity prompt. A safety reviewer needs a sceptical prompt. Forcing both into one agent dilutes both. When the prompts genuinely conflict, splitting helps.
- Context window or rate-limit constraints make a single agent infeasible. A research task that touches 200 documents will exceed a single agent's working memory. Splitting documents across worker agents keeps each within its window.
- Parallel branch exploration provides real value. If three independent strategies might solve a problem and you want to try them concurrently, a swarm of agents pursuing each branch is genuinely faster than one agent serialising the same exploration.
The complementary post on single agent vs multi-agent walks through specific tasks and where each lands. Most operational tasks (inbox triage, lead follow-up, expense categorisation) are firmly single-agent territory. Multi-agent shines in research, code generation across modules, and long-horizon planning.
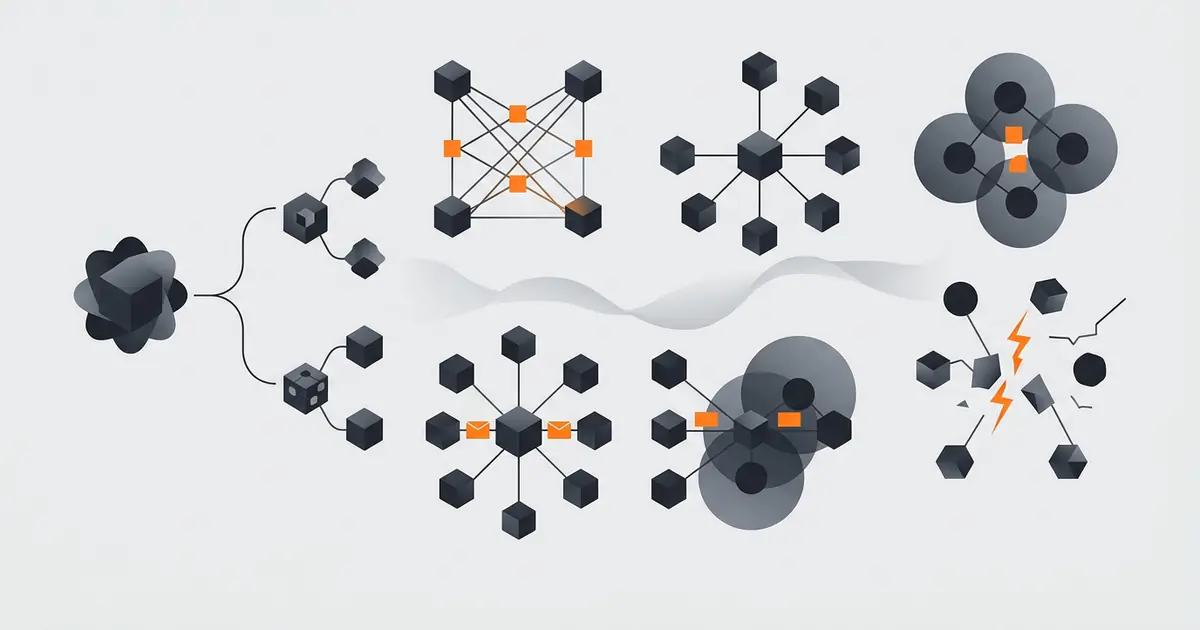
The four patterns that dominate in 2026
Four patterns have stabilised across the major frameworks. They are not mutually exclusive; production systems often combine them.
Orchestrator-worker
One supervisor agent receives the goal, decomposes it, and delegates sub-tasks to specialised worker agents. Workers report back; the orchestrator aggregates and decides whether the goal is met. Anthropic's research-agent and OpenAI's research-mode follow this pattern. The orchestrator-worker shape is the easiest to debug because the dependency graph is a tree and the orchestrator's reasoning is one trace to inspect. The trade-off is bottlenecking: the orchestrator can become a single point of failure if its decomposition logic is brittle.
Hierarchical
An orchestrator-worker tree with more than two levels: managers manage other managers, who manage workers. Used when the task has natural sub-domains (frontend manager + backend manager + DB manager, each with their own worker pool). The cost scales with depth; debugging gets harder fast. Most production systems stop at two levels.
Debate or critique
Two or more agents review each other's output. A writer agent drafts; a critic agent reviews; a writer agent revises. Variants include adversarial debate (two opposing positions, judged by a third agent) and consensus (n agents converge on a shared answer). Microsoft's AutoGen framework provides primitives for this pattern (AutoGen documentation, retrieved 2026-05-09). The pattern is effective for tasks where verification is meaningfully different from generation. It is wasteful for tasks where the critic is just running the generator's prompt twice.
Swarm or peer-to-peer
Agents pass control by handoff without a central orchestrator. Each agent decides whether to handle the request itself or hand off to a peer. OpenAI's Swarm framework implements this pattern (openai/swarm, retrieved 2026-05-09). The pattern fits triage scenarios: the first agent classifies the request, hands off to a domain agent, which may hand off to a sub-domain agent. There is no central state; failures localise to the agent that owns the step.
Communication protocols
How agents talk to each other matters more than which pattern wraps them. Three protocols are common.
Direct message passing. Agent A sends a structured message to agent B. The message contains task description, context references, and a return address. Most multi-agent frameworks default to this. The risk is unbounded message size: agents pile context into messages, costs balloon, latency stacks up.
Shared scratchpad. Agents write to and read from a shared workspace. The orchestrator inspects the scratchpad to decide what is done. CrewAI uses this pattern by default. The risk is contention and stale reads when multiple agents touch the same fields.
Event bus or pub-sub. Agents emit events; other agents subscribe to relevant event types. Closer to a workflow engine than an agent system, but valuable when handoffs are asynchronous or external systems need to participate. Used in production systems that integrate agents with traditional services.
The protocol decision is the largest determinant of latency and cost. Direct messages are fastest but most expensive. Scratchpads are cheapest but slowest. Event buses are operationally complex but scale best. Most teams pick whichever the framework defaults to and never revisit the decision; it is worth revisiting once latency or cost surprises emerge.
Failure modes that kill production
Multi-agent systems fail differently from single agents. Five failure modes recur across post-mortems.
Compounding error. If each agent in a chain has 90 percent step reliability, a five-step chain produces 0.9 to the fifth power, which is roughly 59 percent end-to-end. The arithmetic is unforgiving. The cluster post on agent failure modes covers this in depth. Mitigation: fewer agents, stricter contracts, verification after each handoff.
Hallucinated handoffs. An agent decides to hand off to an agent that does not exist, or with arguments that the receiving agent cannot parse. The orchestration layer must validate handoffs against a registered schema. Frameworks that use loose JSON for handoffs (most do, in 2026) accumulate handoff defects until tests catch them.
Context loss between handoffs. Agent A solves part of the problem; the handoff message to agent B does not include the relevant constraint; agent B regenerates work that agent A already invalidated. The fix is structured handoff contracts: every handoff message must include the goal, what has been tried, what was ruled out, and what the receiving agent should do next.
Cost runaway. Multi-agent systems can enter loops where agents repeatedly hand off without making progress. Each handoff costs tokens. A bug in the handoff logic can produce a five-figure cost spike in an afternoon. Hard caps on agent count, message count, and total tokens are non-negotiable.
Verification illusion. A critic agent that uses the same model as the generator does not catch errors that the generator made due to model bias. The critic is not a verifier; it is a re-roll. Genuine verification requires a different signal: a test, a deterministic checker, or a different model family. Anthropic's research index covers self-verification limits across multiple papers.
The cost reality
Anthropic's published research-agent post reported their multi-agent variant used about fifteen times more tokens than a single Claude.ai chat for comparable depth. Independent benchmarks on AutoGen and CrewAI report 3x to 7x token overhead for typical orchestrator-worker tasks. The variance comes from how aggressively the system passes context between agents and how often the orchestrator re-reads the scratchpad.
The economics post in agent cost models explained walks through the per-token unit economics. The short version: at $3 per million input and $15 per million output for Claude Sonnet 4 in 2026, a single-agent task that costs $0.05 per run becomes $0.15 to $0.75 per run when wrapped in a multi-agent harness. Whether that is justified depends on whether the multi-agent variant produces output worth the difference. Often it does not.
The procurement question for buyers: when a vendor markets multi-agent as a feature, ask which pattern, which protocol, what the cost ratio is versus a single-agent baseline, and how they bound runaway. Vendors who cannot answer those four questions are running demoware.
What we actually run at Gravity
Gravity is single-agent for almost all customer tasks. The product framing in describe outcome, not workflow assumes the agent owns the loop end-to-end; multi-agent breaks that assumption by introducing an orchestration boundary the user can perceive when something goes wrong.
The exceptions are research tasks (orchestrator-worker, max three workers, hard token cap) and code refactors that touch many files (hierarchical, two levels, with verification by test runs). Both are gated by the 80-test methodology: any new multi-agent capability must pass the same reliability bar as single-agent capabilities, and the chain reliability is what gets measured, not the per-agent reliability.
Frequently asked questions
What is a multi-agent system?
A multi-agent system is two or more autonomous agents that coordinate, via shared messages or a central orchestrator, to achieve a goal that no single agent solves well alone. Each agent has its own role, prompt, tool set, and memory. The agents communicate by passing messages or by writing to and reading from a shared scratchpad.
When should I use a multi-agent system instead of a single agent?
Use multi-agent only when the task naturally splits into distinct roles with different tool sets, when context windows are exceeded by a single agent, or when parallel exploration of branches is required. For everything else a well-prompted single agent with a tool catalogue is cheaper, easier to debug, and more reliable in production.
What are the common multi-agent patterns?
Four patterns dominate: orchestrator-worker (one supervisor delegates to specialists), hierarchical (managers manage managers), debate or critique (agents review each other's output), and swarm or peer-to-peer (agents pass control by handoff). Anthropic's research-agent system is the canonical orchestrator-worker example. OpenAI Swarm, AutoGen, and CrewAI each emphasise a different pattern.
What is the biggest failure mode of multi-agent systems?
Compounding error. If each agent in a five-agent chain has 90 percent step reliability, end-to-end reliability is 0.9 to the fifth power, which is 59 percent. Multi-agent systems amplify weaknesses. The fix is fewer agents, stricter handoff contracts, and explicit verification steps after each handoff.
Are multi-agent systems more expensive than single agents?
Yes, often by a factor of three to ten. Each agent runs its own LLM calls, and inter-agent messages duplicate context. Anthropic's research-agent post reported the multi-agent variant used roughly fifteen times more tokens than a single chat session. The cost is justified only when the task genuinely cannot be solved by one agent.
Three takeaways before you close this tab
- Default single-agent. Multi-agent is a specialist tool, not a general upgrade.
- Pick a pattern, then a protocol. Orchestrator-worker plus structured handoffs covers 80 percent of cases.
- Budget for 3x to 15x cost compared to single-agent baselines. Cap aggressively.
Sources
- Anthropic, "How we built our multi-agent research system", retrieved 2026-05-09, anthropic.com/engineering/built-multi-agent-research-system
- Microsoft Research, "AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation", retrieved 2026-05-09, microsoft.github.io/autogen
- OpenAI, "Swarm: Educational framework exploring ergonomic, lightweight multi-agent orchestration", retrieved 2026-05-09, github.com/openai/swarm
- CrewAI documentation, retrieved 2026-05-09, docs.crewai.com
- Anthropic engineering, "Building Effective Agents", retrieved 2026-05-09, anthropic.com/engineering/building-effective-agents