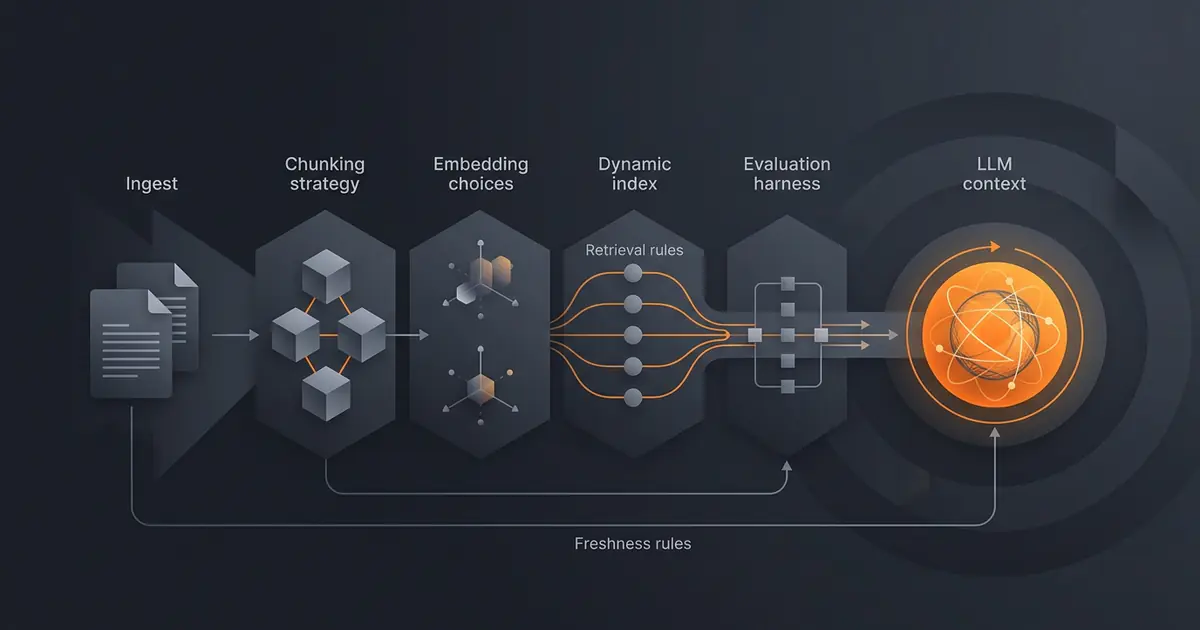
"Training an agent on our docs" usually means fine-tuning in marketing copy and retrieval-augmented generation in code. The marketing version sounds fancier; the code version actually works for what most companies need. This guide walks the production pipeline: ingestion, chunking, embeddings, freshness, evaluation. The shape is the same whether your docs live in Notion, Confluence, Google Drive, or a thousand markdown files.
Retrieval-augmented generation as a pattern is well-documented since Lewis et al. introduced the term (Lewis et al., RAG, arXiv:2005.11401, retrieved 2026-05-09). The 2024-2025 era added agentic retrieval, query rewriting, and reranking; the cluster post on agentic RAG vs RAG covers the upgrades.
Why retrieval beats fine-tuning
Three reasons the field has converged on retrieval as the default.
Freshness. Company docs change weekly or daily. Fine-tuning produces a frozen snapshot; retrieval pulls from the live source. Asking "what is our refund policy" against a fine-tuned model that learned the policy six months ago risks an answer that contradicts the current policy.
Cost. Fine-tuning a frontier model costs $1,000 to $10,000 per run. Retrieval costs cents per query. The math only flips when retrieval latency is unacceptable (very narrow tasks at very high QPS).
Debuggability. When the agent gives a wrong answer in a RAG system, you can inspect the retrieved chunks and the prompt, then fix the chunking, the prompt, or the doc. When a fine-tuned model is wrong, the only fix is to fine-tune again with corrected data, which is expensive and slow.
Reserve fine-tuning for stylistic adaptation (matching brand tone, fitting a specific output format) or for high-QPS offline jobs where retrieval latency dominates. Even then, retrieval-on-top-of-fine-tune is more common than pure fine-tune.
The pipeline
Six stages. Build them in this order:
- Source connectors. Read from Notion, Confluence, Drive, GitHub, or your CMS. Pull both content and metadata (author, last modified, ACL).
- Normalisation. Convert to a common format (markdown). Strip navigation, footers, repeated boilerplate. Preserve structural cues (headings, lists, code blocks) for chunking.
- Chunking. Split by structural boundaries; fall back to fixed length. Tag each chunk with source URL, section, last-modified, and ACL.
- Embedding. Run each chunk through your embedding model. Store the vector with the chunk metadata.
- Indexing. Write to a vector store (pgvector, Pinecone, Qdrant, Weaviate, or your provider's hosted index). Create metadata indexes for filtering by source, author, date, ACL.
- Retrieval and reranking. At query time, embed the query, fetch top-K (start K=20), rerank with a cross-encoder or LLM-based reranker, return top-5 to the agent prompt.
Each stage has well-known libraries and managed services in 2026. The choice matters less than the discipline of building all six stages and running the eval after each.
Chunking strategy
Chunking is where most retrieval systems fail or succeed.
First, structural chunks. Split at H1, H2, H3 headings. A chunk is one section. If a section is shorter than 100 tokens, merge with the previous chunk. If longer than 1,200 tokens, split further by paragraphs.
Second, fixed-length fallback. When structural cues are missing (long narrative docs without headings), fall back to 600 token chunks with 100 token overlap. Overlap protects against a relevant fact landing on a chunk boundary.
Special cases. Code blocks should not be split mid-block; tables should not be split mid-row. Chunks should preserve the heading hierarchy as a prefix ("Section 3.2 > Refund Policy > Edge Cases:") so the embedded chunk carries semantic context the body alone would miss.
Tag every chunk with a stable ID and metadata. The ID lets the eval harness check whether retrieval returned the right chunk. The metadata enables ACL filtering at query time.
Embedding model choices
| Model | Use case | Cost (per million tokens) |
|---|---|---|
| OpenAI text-embedding-3-large | General English + multilingual | $0.13 |
| Cohere embed-multilingual-v3 | Non-English heavy | $0.10 |
| Voyage voyage-3 | Code or technical content | $0.06 |
| BGE-large (open weight) | Self-host, regulated data | compute-only |
| mxbai-embed-large (open weight) | Self-host, English-heavy | compute-only |
Pick a model with at least 1024 dimensions for production quality. Smaller dimensions (384, 512) work for prototypes; production retrieval quality drops noticeably below 1024 on heterogeneous corpora.
Do not switch embedding models without re-embedding the entire corpus. Mixed-embedding indexes produce nonsense rankings. Plan for the re-embedding cost when picking a model.
Freshness rules
Three update tiers based on doc volatility:
- High-change (engineering wikis, product specs): event-driven re-indexing. Webhook from the source system triggers re-embedding for the changed document within 60 seconds.
- Medium-change (sales playbooks, onboarding docs): nightly re-indexing of changed docs.
- Low-change (legal policies, architectural docs): weekly full re-indexing.
Avoid full daily re-indexing of the whole corpus. Embedding costs add up; CPU on the indexer adds up; and re-indexing unchanged docs creates churn that confuses the eval. Track doc.last_modified and only re-embed changed docs.
For deletion: when a doc is removed from the source, immediately delete from the index. A retired policy that still appears in retrieval is a worse failure than a missing policy. The cluster post on agent failure modes covers stale-context failures broadly.
Evaluation harness
Build the eval before you tune. Without it, every change is a guess.
- Collect 50 to 100 representative questions. Get them from real users if possible (support tickets, sales calls). Synthesise the rest.
- For each question, identify the correct answer and the source doc(s) that contain it.
- Run the question through your retrieval pipeline. Score:
- Retrieval precision@5: is the correct doc in top 5?
- Generation correctness: does the agent's answer match? (LLM-as-judge or human review).
- Citation accuracy: does the agent cite the doc it actually used?
- Re-run the eval after every change: prompt edit, chunking change, embedding model swap, doc set update. Track the scores in a chart so you see drift.
The 80-test methodology covered in how we test AI agents applies here directly. Retrieval evaluation is a subset of the broader agent evaluation discipline.
Honouring document permissions
Most company doc systems have ACLs (per-doc access control). The agent must respect them. Three patterns:
- Index-time filtering. Tag every chunk with the source doc's ACL identifier. At query time, filter retrieved chunks by the requesting user's permission set. Simple to implement; correct for most cases.
- User-scoped indexes. Build separate vector indexes per ACL group. Higher storage cost; cleaner isolation; useful when ACL groups rarely overlap.
- Live ACL check. At query time, fetch the user's live permissions and filter against the source system's API. Slower; safest for highly sensitive content.
Whichever pattern you pick, do not ship the retrieval system without an ACL test in your eval set. A single retrieval that returns a confidential doc to an unauthorised user is a bigger incident than ten retrieval misses. The cluster post on agent trust models covers the broader governance bar.
Frequently asked questions
Do I need to fine-tune to train an agent on my docs?
Almost never. Retrieval-augmented generation (RAG) outperforms fine-tuning for almost all company-knowledge tasks because docs change frequently and fine-tuning produces a frozen model. Reserve fine-tuning for stylistic adaptation (the tone of replies) or for offline tasks where retrieval latency is unacceptable. Start with retrieval; consider fine-tuning only after retrieval is stuck.
What chunk size should I use when indexing company docs?
Start with 400 to 800 token chunks with 50 to 100 token overlap. The lower bound preserves semantic coherence; the upper bound fits within most embedding model context windows efficiently. Chunk by structural boundaries (headings, paragraphs) before falling back to fixed length. Re-evaluate chunk size after the first hundred queries; small chunk size for FAQ-style docs, larger for narrative documents.
Which embedding model should I use?
OpenAI text-embedding-3-large for English-heavy and multilingual workloads at $0.13 per million tokens. Cohere embed-multilingual-v3 for non-English-dominant deployments. Voyage voyage-3 for code-heavy or technical content. Open-weight options like BGE-large or mxbai-embed-large for self-hosting or regulated data. The choice matters less than chunking and evaluation, but pick a model with at least 1024 dimensions for production quality.
How often should I re-index company docs?
Continuously for high-change content (engineering wikis, product specs), nightly for medium-change content (sales playbooks, onboarding docs), and weekly for low-change content (legal policies, foundational architecture docs). Build the indexing pipeline as event-driven from your source-of-truth systems (Notion, Confluence, Google Drive); poll-based pipelines drift and stale answers erode trust fast.
How do I prove the agent is using my docs correctly?
Build an evaluation set of 50 to 100 questions with known correct answers and known supporting documents. For each question, score retrieval precision (was the right doc returned in top-5), generation correctness (did the answer match), and citation accuracy (does the agent cite the doc it actually used). Run the eval on every prompt change, embedding-model change, and major doc-set update. Without the eval, you are guessing.
Three takeaways before you close this tab
- Retrieval, not fine-tuning, for company docs.
- Structural chunking first, fixed-length fallback.
- Eval set before optimisation. 50-100 questions, run on every change.
Sources
- Lewis et al., "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks", arXiv:2005.11401, retrieved 2026-05-09, arxiv.org/abs/2005.11401
- OpenAI Embeddings documentation, retrieved 2026-05-09, platform.openai.com/docs/guides/embeddings
- Cohere Embed v3 release notes, retrieved 2026-05-09, cohere.com/blog/introducing-embed-v3
- Voyage AI documentation, retrieved 2026-05-09, docs.voyageai.com
- Anthropic, "Building Effective Agents", retrieved 2026-05-09, anthropic.com/engineering/building-effective-agents