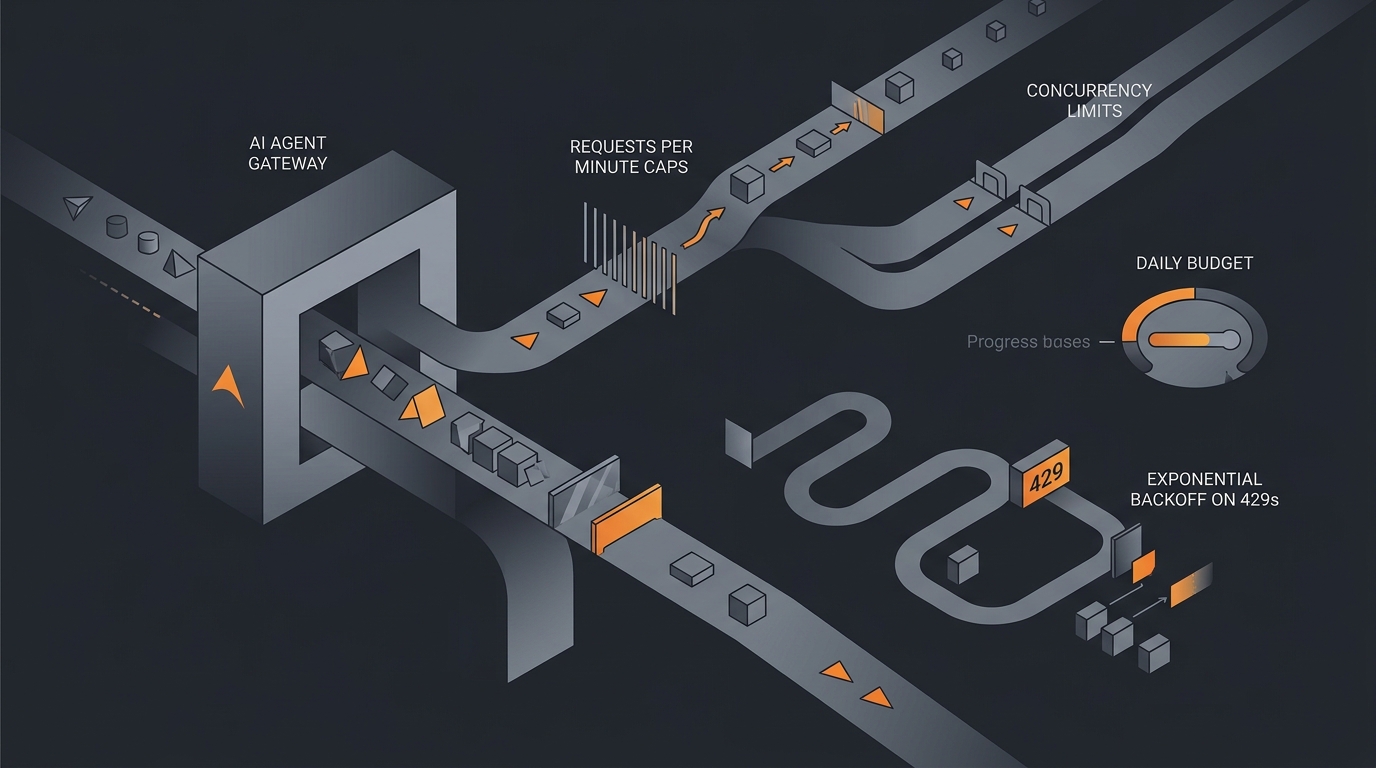
To rate limit an AI agent, put three caps in front of every action it takes: a request-per-minute cap so it stays inside the quotas of the models and APIs it calls, a concurrency cap so it never runs more tasks at once than your downstream systems can absorb, and a daily budget so a single run cannot drain your account. Add exponential backoff on 429 responses so a busy endpoint slows the agent down instead of breaking it. Together these turn a bursty, unpredictable agent into one that paces itself.
The reason this matters more for agents than for ordinary software is the loop. An agent decides its own next step, and a step can spawn more steps. A bug, an ambiguous instruction, or a tool that keeps returning the same error can send an agent into a tight loop that fires hundreds of API calls per minute and bills you for every one. A rate limit is the seatbelt for that loop. This guide covers each cap, how to choose values, and how rate limiting differs from a hard stop.

Why rate limit an agent
There are three distinct problems a rate limit solves, and it helps to keep them separate because each one points to a different cap.
Respecting downstream quotas. Every model API and every third-party service the agent touches enforces its own limits. Anthropic, for example, publishes per-minute caps on requests, input tokens, and output tokens that vary by usage tier, and a request over the limit returns a 429 error (see the Anthropic rate limits documentation). If your agent ignores those ceilings, it spends part of its run colliding with them instead of doing work. Pacing the agent below the quota keeps it productive.
Controlling cost. Token-based pricing means cost scales directly with how many calls the agent makes. An agent with no ceiling can run up a bill far larger than the task was worth before anyone notices. A daily budget caps the downside. This is one piece of a broader discipline covered in AI agent cost control, and it pairs well with optimizing the agent prompt for cost so each call does more.
Avoiding runaway loops. The failure mode unique to agents is the loop that will not end. A retry that never succeeds, a planning step that keeps re-planning, two sub-agents that keep handing work back and forth: any of these can run unbounded. A rate limit will not fix the bug, but it caps how fast and how expensive the loop gets while you catch it. For the deeper conceptual treatment of these mechanisms, AI agent rate limiting covers the theory; this post is the practical how-to.
Three caps that matter
Rate limiting is not a single number. It is three caps that work on different axes, and you want all three because each catches a failure the others miss.
- Request rate controls throughput over time: how many calls per minute or per second. It keeps you inside provider quotas and smooths bursty traffic.
- Concurrency controls the peak: how many tasks run at the same instant. A low request rate can still spike if a dozen tasks fire together, so concurrency is a separate lever.
- Daily budget controls the total: a ceiling on calls, tokens, or spend across a whole day, regardless of rate or concurrency. It is the backstop that bounds the worst case.
A useful way to picture it: the request rate is the speed limit, concurrency is the number of lanes, and the daily budget is the fuel tank. You can be under the speed limit and still cause a jam if every lane is full, and you can be moving slowly in one lane and still run out of fuel on a long enough trip. The three sections below take each in turn.
Set a request-per-minute cap
A request-per-minute cap is the most direct control. It says the agent may issue at most N calls to a given service in any sixty-second window. The standard way to implement it is a token bucket: the bucket holds a fixed number of tokens, each request removes one, and tokens refill at a steady rate. When the bucket is empty, the next request waits until a token is available.
Choosing N starts from the provider's published limit, not a guess. Read the quota for the specific endpoint and tier you are on, then set your cap below it, leaving headroom. A common practice is to target somewhere in the region of 70 to 80 percent of the provider ceiling so that normal variance does not push you over. Leave more room if other workloads share the same API key, since they draw from the same quota.
Apply the cap per service, not globally. The agent might call a language model, a search API, and a database in the same task, and each has its own limit. One shared counter would either throttle the fast services to the speed of the slowest or let the slow one blow past its quota. A separate bucket per downstream service keeps each one inside its own ceiling.
Cap concurrency
A concurrency cap limits how many tasks or sub-agents are in flight at the same moment. It is a different axis from the request rate. You can keep a low average requests-per-minute and still slam a downstream service if twenty tasks happen to start within the same second. The request cap smooths the long run; the concurrency cap bounds the peak.
The usual implementation is a semaphore: a counter set to the maximum number of simultaneous tasks. A task acquires a slot before it starts and releases it when it finishes. When all slots are taken, new tasks queue until one frees up. This naturally limits how many model calls, open connections, and chunks of working memory exist at once.
Concurrency caps matter most for agents that fan out, an agent that processes a hundred records by spinning up a worker per record, or a coordinator that delegates to several sub-agents. Without a cap, fan-out turns into a thundering herd that overwhelms the downstream service and spikes spend in a single burst. With a cap of, say, five, the work still completes; it just flows through five at a time. If your agent spreads work across multiple steps or sub-agents, the patterns in setting up agent fallback chains compose cleanly with a concurrency limit.
Set a daily budget
The request and concurrency caps shape the flow of work. The daily budget bounds the total. It is a ceiling on how much the agent can consume in a day, expressed in whatever unit you can measure: number of calls, total tokens, or direct spend. When the agent reaches the ceiling, it stops starting new work until the window resets.
A budget protects against the slow-burn failure that the other two caps miss. An agent can sit comfortably under its per-minute and concurrency limits and still, over many hours, accumulate a bill nobody intended, because a misconfigured schedule keeps re-triggering it, or a task that should run once retries quietly all afternoon. Neither rate nor concurrency notices; both are satisfied. The daily budget is the only cap that sees the cumulative total.
Set the budget from the job, not from your tolerance for surprise. Estimate what a normal day of the agent's work should cost, add a margin for legitimate spikes, and set the ceiling there. Then add a warning threshold below it, at perhaps 80 percent, so you get a heads-up before the agent stops rather than discovering it only when work halts. Pair the budget with alerting so a near-miss surfaces in monitoring and observability instead of silently eating into the ceiling.
Back off on 429s
Even with caps in place, you will sometimes get a 429 response, the HTTP status for too many requests. It happens when your own cap is set slightly high, when a shared quota gets crowded, or when the provider tightens limits under load. How the agent reacts to a 429 is as important as the cap itself.
The wrong reaction is to fail the task or to retry immediately. An immediate retry just produces another 429 and makes the congestion worse. The right reaction is exponential backoff: wait a short interval, retry, and if it fails again, double the wait, and keep doubling up to a ceiling. A first wait of one second becomes two, then four, then eight, giving the downstream service time to recover.
Three details make backoff work in practice:
- Add jitter. Add a small random amount to each wait so that many parallel workers, all backed off at once, do not retry in the same instant and re-create the spike. Randomized delay spreads the retries out.
- Honor Retry-After. If the 429 response carries a
Retry-Afterheader, the provider is telling you exactly how long to wait. Use that value instead of your own guess. - Cap the retries. Set a maximum number of attempts so a call that will never succeed gives up cleanly instead of looping. Past the cap, surface the failure to your retry and fallback logic rather than spinning forever.
Backoff is the bridge between rate limiting and error handling. The cap is what you do to avoid 429s; backoff is what you do when one slips through anyway. For the wider retry picture, including what to do after backoff is exhausted, see AI agent fallback and retry and the field guide to debugging agent tool errors.
Rate limit vs. kill switch
A rate limit and a kill switch are often confused, and treating one as the other leaves a gap. They solve different problems and you want both.
A rate limit slows the agent down. It assumes the agent is doing legitimate work and simply needs to be paced so it fits inside a quota and a budget. The agent keeps running; it just runs more smoothly. A rate limit is a steady-state control, active on every normal run.
A kill switch stops the agent entirely. It is for the case where something is clearly wrong and the right answer is not to slow down but to halt: a confirmed runaway loop, an output that is obviously broken, a spend spike that blows past the daily budget, or a security concern. A kill switch is an exception control, used rarely, by design.
The distinction matters because each fails differently if you substitute it for the other. Rely only on a rate limit and a genuinely broken agent will keep running, slowly, doing damage at a measured pace, which can be worse than a fast failure because it is harder to notice. Rely only on a kill switch and you have no smooth control, so the agent oscillates between full speed and full stop. The reliable setup is layered: a rate limit handles the normal case continuously, and a kill switch sits behind it for the emergency. Both belong to the broader practice of AI agent safety and guardrails, where rate limiting is one guardrail among several.
Monitor against your limits
A cap you cannot see is a cap you cannot tune. Rate limiting and monitoring are the same loop: you set a limit, watch how often the agent approaches it, and adjust. Without the watching half, you either set caps so loose they protect nothing or so tight they throttle real work, and you never learn which.
Track a handful of signals against each cap:
- Requests per minute versus the cap, so you can see how much headroom remains and whether the agent regularly bumps the ceiling.
- Concurrent tasks versus the concurrency cap, so a queue that is constantly full tells you the cap is the bottleneck.
- Spend or token use against the daily budget, plotted over the day, so a creeping burn is visible long before it reaches the ceiling.
- 429 rate and retry counts, because a rising 429 rate is the earliest sign that a cap is set too high or a shared quota is getting crowded.
The point of watching is to close the loop. If the agent never gets near a cap, the cap is doing nothing and you can either tighten it or stop worrying about it. If it bumps a cap constantly, either the cap is too tight for legitimate work or the agent is doing more than it should, and the metric tells you which conversation to have. This feedback is core to monitoring and observability, and the definitions behind the terms live in the glossary.
How Gravity handles rate limiting
Gravity is an AI agent platform. The agents are expert-built, and rate limiting is handled inside the platform rather than left for you to wire up. Each agent runs with request pacing, concurrency caps, and backoff on downstream errors already in place, so an agent stays inside the quotas of the services it calls without you configuring a token bucket or a semaphore by hand.
Cost is bounded by design through the pricing model. You pay per use: $1 equals 1,000 credits, and you are only billed when an agent actually runs. There is no idle drain and no surprise from an agent that was left running, because consumption maps directly to work done. The daily-budget concern that you would otherwise enforce yourself is built into how usage is metered.
Because you describe what you need in plain words and an expert-built agent runs it in about 60 seconds, the rate-limiting machinery stays out of your way. The caps, the backoff, and the monitoring against limits are part of how the platform operates the agents, not configuration you maintain. If you want to understand the underlying concept before relying on it, what is an AI agent sets the foundation, and AI agent rate limiting goes deeper on the mechanism.
FAQ
What does it mean to rate limit an AI agent?
Rate limiting an AI agent means capping how many actions it can take in a given window: requests per minute to a model or API, the number of tasks it runs at the same time, and a daily ceiling on total work or spend. The caps keep the agent inside the quotas of the services it calls, keep cost predictable, and stop a stuck agent from looping forever.
How is rate limiting different from a kill switch?
A rate limit slows an agent down; a kill switch stops it entirely. Rate limiting smooths a bursty workload so it fits within a quota and a budget while the agent keeps working. A kill switch is a hard stop you trigger when something is clearly wrong: a runaway loop, a spend spike, or a bad output. You want both. The rate limit handles the normal case and the kill switch handles the emergency.
What should I do when an agent hits a 429 error?
A 429 status means too many requests. The agent should wait and retry rather than fail or hammer the endpoint. Use exponential backoff: wait a short interval, then double it on each retry, and add a small random jitter so parallel workers do not all retry at the same instant. If the response includes a Retry-After header, honor it. Cap the number of retries so a persistently failing call does not loop indefinitely.
What is a concurrency cap for an agent?
A concurrency cap limits how many tasks or sub-agents run at the same moment, regardless of how fast each one issues requests. A request-per-minute cap controls throughput over time; a concurrency cap controls the peak. Capping concurrency protects downstream systems from a sudden burst, keeps memory and connection use bounded, and makes spend per minute predictable when many tasks could otherwise fire at once.
Should the rate limit be on the agent or on the API?
Both layers help, but you cannot rely on the downstream API alone. The provider's limit protects the provider, returns errors after the fact, and says nothing about your budget. A limit inside the agent shapes traffic before it goes out, enforces your own daily cost ceiling, and lets the agent pace itself smoothly instead of bursting into a wall of 429s. Treat the provider limit as a backstop and put the primary control in the agent.