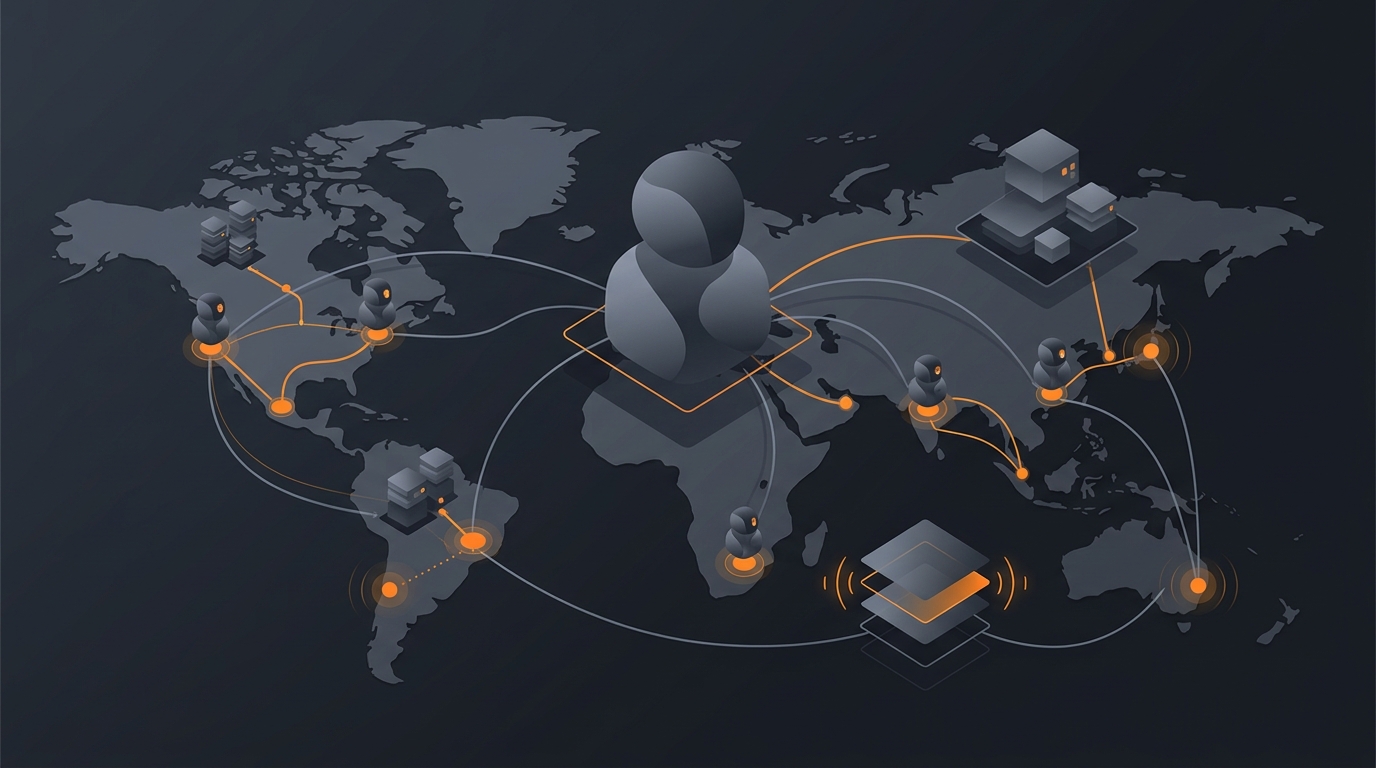
Multi-region deployment means running an AI agent's infrastructure in more than one geographic region at the same time, so a request can be served from the region closest to the user and rerouted to another region if one fails. For agents specifically, it earns its complexity by buying three distinct things: lower latency for users far from a single home region, higher availability because no one region can take the whole service down, and data residency, the ability to keep particular data inside a particular jurisdiction. Each is a real benefit, and each comes with a cost that this guide tries to make legible before you commit.
The honest framing up front is that multi-region is not a default to reach for. It is a deliberate trade: more moving parts, harder consistency, higher spend, in exchange for solving a specific problem you can name. The teams that regret going multi-region are the ones that did it because it sounded robust; the ones that are glad they did had a concrete driver. So the question is not "should everything be multi-region" but "which of latency, availability, and residency is forcing my hand."

Three reasons to go multi-region
Almost every multi-region decision traces back to one or more of three drivers, and naming which one applies tells you how to design the deployment.
- Latency. Physical distance adds round-trip time. If your users span continents, serving all of them from one region means someone is always far away and feeling it.
- Availability. A single region is a single point of failure. If your reliability target is higher than one region can guarantee, you need somewhere to fail over to.
- Data residency. Laws and contracts may require that specific data stays inside a specific jurisdiction. A region in that jurisdiction is how you comply.
These drivers are independent. You might go multi-region purely for residency while latency is a non-issue, or purely for availability while all your users sit in one place. Knowing which driver is real keeps you from over-building: a residency-driven deployment looks different from a latency-driven one, and conflating them produces a system that is complex for reasons nobody can articulate.
Latency: being close to users
Latency is the most intuitive driver. The speed of light puts a floor under how fast a request can cross the planet, and that floor is felt every time a user in one continent talks to a server in another. For an agent that makes several internal calls per task, each hop pays that distance tax, and the delays compound into a result that arrives noticeably slower than it would for a nearby user.
Running the agent in regions near your user clusters cuts the distance and the tax. A user is served from the region closest to them, so the round trips stay short and the agent feels responsive everywhere rather than only near its home region. Latency is one of the indicators worth tracking explicitly, since "time to a usable result" is a first-class reliability signal, not just a nicety, a point developed in agent uptime and reliability. If your users are concentrated in one area, though, this driver simply does not apply, and adding distant regions buys nothing.
Availability and failover
Multiple regions raise availability only if you can move traffic between them. This is the detail that trips teams up: deploying to three regions does nothing for uptime by itself, because if requests are pinned to whichever region they land on, a region going down still takes its users with it. The benefit comes from failover, the ability to detect an unhealthy region and route around it.
Done right, failover turns a regional outage from a total failure into a partial one. Health checks watch each region, and when one stops responding, traffic shifts to the healthy regions, which absorb the load while the failed region recovers. The service degrades, capacity drops, response times may rise, but it stays up. This is the same recovery thinking behind a disaster recovery plan, applied at the granularity of regions, and it pairs naturally with deployment techniques like blue-green deployment that already assume you can shift traffic between environments cleanly. The capacity math matters too: each surviving region needs enough headroom to take on a failed region's share, which is exactly what load testing at scale is for.
Data residency by region
The third driver is legal rather than technical. Data residency rules, common in privacy regimes and many enterprise contracts, require that certain data is stored and processed inside a defined jurisdiction. Multi-region deployment is the mechanism that satisfies them: you pin a given user's data and the processing of it to a region inside their required jurisdiction.
In practice that means an EU customer is served from an EU region with their data staying there, while a US customer is served from a US region, and the deployment topology itself becomes the enforcement of the rule. This is the operational half of the broader topic covered in agent data residency: residency is a promise about where data lives, and a region in the right place is how the promise is kept. The subtlety is that residency constrains the very state-sharing that latency and availability want to make global, which sets up the central tension of multi-region design.
The state problem
Everything easy about multi-region is stateless; everything hard about it is stateful. Handling a request that needs no memory is simple to replicate, just run the same logic in every region. But an agent has state: task progress, conversation history, the context it has accumulated, and that state has to be coherent no matter which region handles the next step. Multi-region agents live or die on how they manage it.
The core decision is what to replicate everywhere versus what to pin to one place. Replicating state across all regions gives any region the context to serve any request, but replication takes time, and during that lag two regions can briefly disagree about the truth, the source of subtle, hard-to-reproduce bugs where an agent "forgets" something it just did because the next step ran in a region that had not caught up. Pinning state to one region keeps it consistent but reintroduces a dependency on that region. There is no free answer; there is only choosing the trade-off deliberately, often by replicating low-sensitivity state broadly while keeping authoritative, residency-bound state pinned. This is why an agent's monitoring and observability has to be region-aware: when something goes wrong, the first question is which region held the state.
When you do not need it
Because the costs are real, the most useful section may be the one that tells you to stop. If none of the three drivers applies, do not go multi-region. A single well-run region with solid backups and a tested restore is simpler, cheaper, and easier to reason about than a multi-region system whose consistency you will spend quarters debugging.
Reach for additional regions when you can point at the driver: users far enough apart that latency genuinely hurts, an availability target a single region provably cannot meet, or residency rules you are contractually or legally bound to satisfy. Absent one of those, the complexity is a cost with no offsetting benefit. Add regions to solve a problem you have stated out loud, never as a reflex toward sounding robust, and revisit the decision as your user base and obligations actually change.
How Gravity handles regions
Gravity is an AI agent platform, and the multi-region machinery described here, routing to the nearest region, failover between regions, residency pinning, and the state-consistency work underneath, is operated by the platform rather than assembled by each user. The agents are expert-built and run inside a runtime that handles regional placement and recovery as part of the service.
For the user, that means you describe what you need in plain words and an expert-built agent returns the finished result in about 60 seconds, without designing a deployment topology yourself. You pay per use, $1 equals 1,000 credits, billed only when an agent runs. To go deeper on the surrounding concepts, what is an AI agent sets the foundation and the glossary defines the terms used above.
FAQ
What is multi-region deployment for AI agents?
Multi-region deployment means running an agent's infrastructure in more than one geographic region at once, so requests can be served from the region nearest the user and from a different region if one fails. For agents it serves three goals: lower latency by being close to users, higher availability because no single region is a single point of failure, and data residency by keeping certain data inside a required jurisdiction.
Does multi-region deployment improve agent availability?
Yes, when it is paired with failover. Running in multiple regions only raises availability if traffic can be routed away from a region that goes down to one that is healthy. With health checks and automatic failover in place, a regional outage degrades capacity instead of causing a total outage. Without failover, multiple regions just add cost and complexity while the agent still depends on whichever region a request happened to hit.
What is the hardest part of multi-region agents?
State. Stateless request handling is easy to replicate across regions, but an agent's memory, its task state, conversation history, and stored context, has to be consistent no matter which region serves the next step. Keeping that state coherent across regions, deciding what replicates everywhere versus what stays pinned to one region, is the central engineering challenge and the reason naive multi-region rollouts produce subtle, hard-to-reproduce bugs.
How does multi-region deployment support data residency?
Data residency rules require that certain data is stored and processed inside a specific jurisdiction. Multi-region deployment supports this by pinning a user's data and the processing of it to the region that satisfies their rules, so an EU customer's data stays in an EU region while a US customer is served from a US region. The deployment topology becomes the mechanism that enforces a legal requirement.
Do you always need multi-region for agents?
No. Multi-region adds real cost and complexity, so it should be driven by a concrete need: users far enough apart that latency hurts, an availability target a single region cannot meet, or data residency rules you must satisfy. If none of those apply, a single well-run region with solid backups is simpler and cheaper. Add regions to solve a stated problem, not as a default.