Long-term memory in an AI agent is any mechanism that stores information outside the active context window so it can be retrieved in a future session. Without it, an agent starts fresh on every run: no record of prior conversations, no retained preferences, no accumulated knowledge. With it, agents can build on past interactions, personalize behavior over time, and complete tasks that span multiple sessions.
This post focuses on the strategies for implementing long-term memory, not just what memory is. Each strategy has a different cost, retrieval quality, and failure profile. Choosing the right one, or the right combination, determines whether persistent memory helps an agent or actively misleads it. For a broader introduction to agent memory as a concept, see AI agent memory explained.

Short-Term vs Long-Term Memory
Short-term memory in an agent is the active context window: everything the model can see and reason over in the current run. This includes the system prompt, the current conversation, tool call results, and any documents injected for the task at hand. It is bounded by the model's context limit. When the session ends, the context is discarded.
Long-term memory persists across that boundary. It lives in an external store, not in the model itself, and must be explicitly retrieved and injected into context to be used. This distinction matters because the model does not passively absorb long-term memories over time; it only uses what is in context at inference time. The agent's architecture is responsible for deciding what to store, how to retrieve it, and when to load it.
The retrieval problem
The core challenge of long-term memory is retrieval: knowing which stored memories are relevant to the current task and loading only those, since the context window cannot hold everything at once. A naive approach that loads all stored memories on every run runs into context limits quickly and may inject irrelevant information that degrades response quality. Good long-term memory design is mostly a retrieval design problem.
The write problem
Equally important is what gets written to long-term memory and when. Storing everything produces a bloated, noisy memory store. Storing too little creates gaps. The write strategy, including what triggers a write, what format is used, and how duplicates are handled, shapes the quality of what can later be retrieved. Writing and retrieval are two sides of the same design problem. This connects to the broader challenge of context window management, where what stays in the active window and what gets offloaded to memory are tightly linked decisions.
Why Long-Term Memory Changes What Agents Can Do
Without long-term memory, agents are useful for single-session tasks: answer a question, draft a document, execute a workflow. With it, agents can become genuinely persistent collaborators: they remember your preferences without being told again, they recall the outcome of a task completed last week, they build on prior context without you re-explaining it.
Recurring agents benefit most. An agent that monitors your inbox daily, a research assistant that tracks a topic over weeks, or a task orchestrator that manages an ongoing project all need cross-session continuity to do their job well. Each run without memory is a fresh start; each run with memory is a continuation. The difference in usefulness is substantial.
Personalization is the other major payoff. An agent that knows how you prefer reports structured, which topics you care about, and what decisions you made in similar situations in the past can skip the calibration overhead that makes one-time interactions slow. Memory is how that calibration persists.
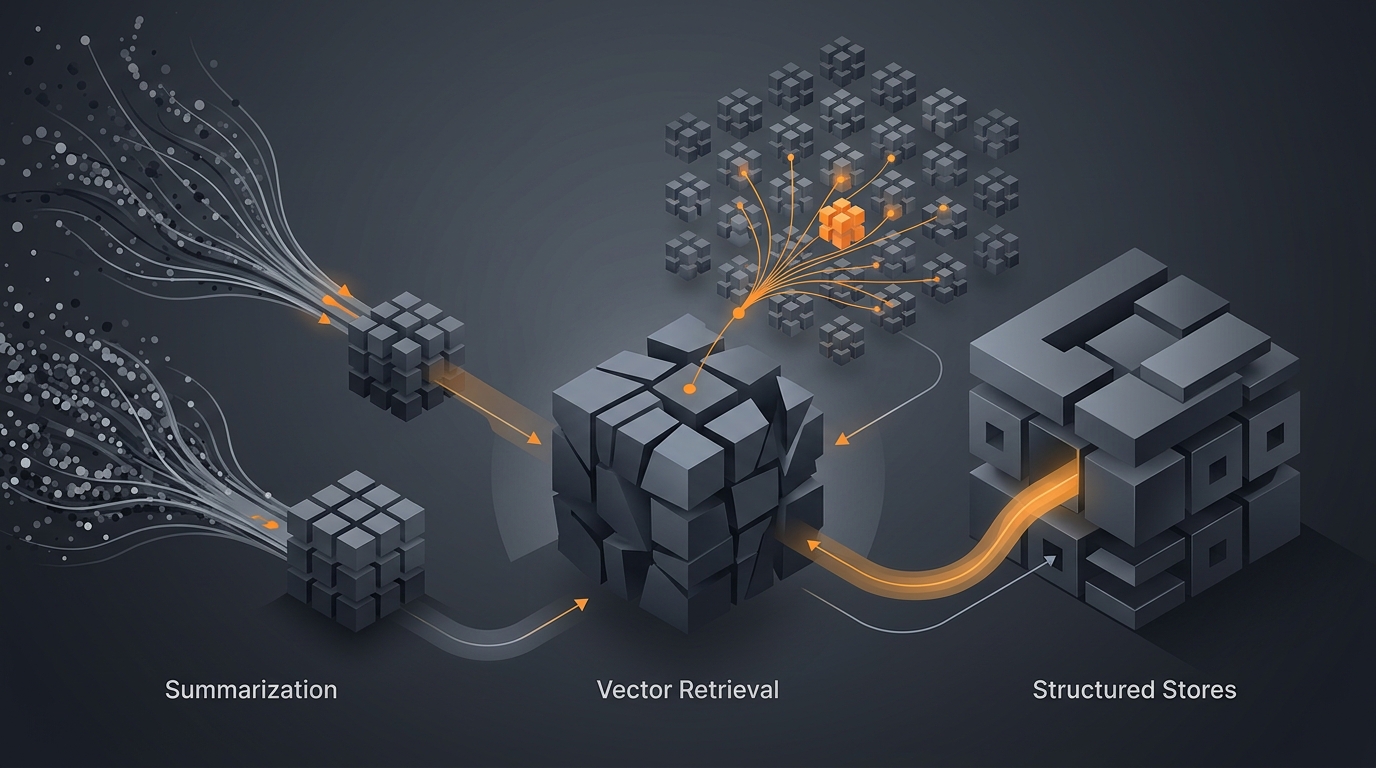
Strategy 1: Summarization
Summarization compresses a prior conversation or task run into a shorter representation and stores that summary for later retrieval. When the agent starts a new session, the prior summary is loaded into context, giving the model a condensed version of relevant history without exhausting the context window with raw transcripts.
How it works
At the end of a session, or at regular intervals within a long session, the agent or a separate summarization process produces a compact representation of what happened: key decisions, user preferences expressed, facts established, tasks completed or in progress. This summary is stored and loaded at the start of the next relevant session.
Summarization can be triggered by session end, by a token threshold, or on a fixed schedule. The summarization itself is usually done by the same model or a smaller one. The output is plain text or structured notes, not embeddings, which means retrieval is simple: load the most recent summary or all summaries in time order.
Strengths
Summarization is predictable and low-latency. The memory representation is human-readable, which makes it easy to inspect and debug. There is no vector store to maintain, no embedding model to run, and no retrieval query to tune. For agents that have linear, session-by-session histories, summarization is often the simplest strategy that works well.
Weaknesses
Summarization loses detail. Once a session is compressed into a summary, the original nuance is gone. If the summary misses something the agent later needs, that information cannot be recovered from storage. Summaries also drift: each summary of a summary introduces further compression, and over many sessions the representation of early context can become too abstract to be useful.
Strategy 2: Vector Retrieval
Vector retrieval stores memories as embedding vectors in a vector database and retrieves them by semantic similarity to a query derived from the current context. Instead of loading all memories at the start of a session, the agent queries for the most relevant ones and injects only those into the active window.
How it works
Each memory unit, whether a conversation turn, a note, a document chunk, or a fact, is passed through an embedding model that produces a dense vector representing its meaning. That vector is stored alongside the original text. At retrieval time, the agent's current context is embedded using the same model, and the vector store returns the stored memories whose embeddings are nearest in the embedding space. The top results are loaded into the context window for the current run.
Strengths
Vector retrieval scales to large memory stores without context bloat. It retrieves by meaning rather than exact match, so a query about "the client's deadline" can surface a note that says "Sarah needs this by Q3" even if the words do not overlap. It is well-suited to unstructured content like conversation history, research notes, or domain knowledge.
Weaknesses
Retrieval quality depends on embedding quality. If the embedding model does not represent the domain well, or if the query and the stored memory are phrased very differently, relevant memories can be missed. Vector retrieval also has no inherent notion of recency or priority: an old, superseded note may score higher than a recent, more accurate one if the embedding similarity happens to match. Handling recency and relevance simultaneously requires additional design work. For agents running long multi-step tasks, this intersects with how the agent structures planning versus execution phases, since memory reads are often part of the planning step.
Metadata filtering
Most practical vector retrieval implementations combine semantic similarity with metadata filters: retrieve memories that are both semantically relevant AND within the last 30 days, or associated with a specific user, or tagged with a specific topic. Metadata filtering narrows the candidate set before scoring, improving both precision and performance. Designing good metadata at write time is as important as the retrieval query at read time.
Strategy 3: Structured Stores
Structured memory stores facts in a relational database, key-value store, or document store in a well-defined schema. The agent reads and writes to this store using exact queries rather than semantic similarity. User preferences, task status, entity records, and settings are common things to store this way.
How it works
The agent is given tools to read from and write to a structured store. When a relevant fact is established, the agent calls a write tool: set preference "report format" to "bullet points." When the agent needs that fact, it calls a read tool: get preference "report format." The store returns the exact value. There is no embedding, no similarity score, and no ambiguity: the agent gets the record it queried for or nothing.
Strengths
Structured stores are reliable for exact lookup. There is no retrieval ambiguity: if the fact is there, the agent gets it. Updates are clean: writing a new value for a key replaces the old one without leaving stale duplicates that could confuse a similarity-based retrieval. Structured stores are ideal for preferences, settings, named entities, and any fact with a clearly defined key.
Weaknesses
Structured stores require the agent to know what to query. Unlike vector retrieval, where the agent can describe a vague concept and get relevant results, structured retrieval requires a specific key or field name. If the agent does not know to ask for "report format preference," it will not retrieve it. Structured memory also handles unstructured content poorly: you cannot store a rich conversation summary in a structured field without losing most of its value.
Episodic vs Semantic Memory
Memory researchers distinguish between episodic and semantic memory, and the distinction maps usefully onto agent memory design.
Episodic memory
Episodic memory records specific events in time: "on June 5th, the user asked for a report on competitor pricing and approved the outline we drafted." It is ordered, contextual, and tied to a specific moment. In agent terms, this is conversation history, task logs, and outcome records. Episodic memory supports continuity: the agent knows what happened, in what order, and can refer back to it.
Semantic memory
Semantic memory stores generalized knowledge independent of when it was acquired: "the user prefers bullet-point summaries" or "the company's fiscal year ends in March." It is not tied to an event; it is simply a fact the agent treats as reliable. Semantic memory supports personalization and efficiency: the agent does not need to re-establish known facts on each run.
Why agents often need both
A recurring task agent benefits from episodic memory so it knows the status of prior runs and the decisions made previously. It also benefits from semantic memory so it knows stable preferences and context without re-asking each time. The two types of memory serve different functions and are often stored separately: episodic in a time-ordered log or vector store with timestamp metadata, semantic in a structured store or a deduplicated knowledge base.
Combining Strategies
The strongest agent memory architectures combine multiple strategies rather than relying on one. Each strategy covers what the others miss.
A common layered approach
A common pattern uses three layers. First, a structured store for stable facts: user preferences, entity records, configuration. Second, a vector store for unstructured episodic content: conversation summaries, research notes, task logs. Third, a running context summary for conversational continuity within a session. At the start of each run, the agent queries the structured store for known facts, queries the vector store for relevant past episodes, and receives the session summary for continuity. All three are injected into the active context window before the agent begins reasoning.
Write triggers and memory hygiene
With multiple layers, write triggers need to be well-defined. Structured facts are written when the agent explicitly establishes a user preference or updates a record. Vector memories are written at session end or at key task milestones. Session summaries are written at end-of-session. Each layer has its own update logic, and none should silently overwrite or duplicate another. Memory hygiene, periodically reviewing and pruning stale or redundant entries, becomes a maintenance concern as the memory store grows.
Failure Modes and How to Mitigate Them
Long-term memory introduces failure modes that stateless agents do not face. Understanding them is essential before deploying agents that depend on persistent memory.
Stale memory
Stored facts become outdated. A preference captured six months ago may no longer reflect current needs. A document stored as authoritative may have been superseded. The agent has no way to know a memory is stale unless the agent or the user marks it as such, or the memory system includes expiration logic. Mitigations include: adding timestamp metadata to all memories, retrieving recency as a factor in ranking, and building tools that allow explicit memory update or invalidation.
Polluted memory
Low-quality or incorrect information enters the store and gets retrieved as if reliable. This can happen from agent errors (the agent records a wrong inference as a fact), from user corrections that were not properly applied (the old incorrect version stays in the store alongside the corrected one), or from ingesting noisy external documents. Mitigations include: requiring a write-confirmation step before storing inferred facts, deduplication at write time, and periodic audits of high-retrieval memories.
Retrieval mismatch
The right memory exists but is not retrieved because the query did not semantically match it well enough. This is particularly common in vector retrieval when the memory was written in different terminology than the query used. Mitigations include: storing multiple phrasings or synonyms alongside a memory, enriching memory representations with metadata that can be filtered, and periodically testing retrieval on known-important memories to catch degradation.
Context saturation
Too many memories are retrieved and injected into context, crowding out space for the actual task. This is a context window management failure. Mitigations include: strict limits on how many memory tokens can be injected per run, ranking retrieved memories by relevance and truncating aggressively, and using summarization to pre-compress memories before injection. The agent memory explained post covers the basic mechanics of how context fills and why saturation matters.
When Each Strategy Fits
Choosing a memory strategy is not a question of which is best in general, but which fits the specific demands of the agent's task.
Summarization fits when
The agent has a sequential, session-by-session history where each session builds naturally on the previous one. The exact wording of prior turns is not important, only the gist. Context window use is the primary constraint. A customer support agent, a recurring standup bot, or a coaching agent with weekly check-ins are good fits.
Vector retrieval fits when
The agent needs to surface specific past content on demand from a large history. The queries are open-ended and the relevant content cannot be specified by exact key. Research agents, personal knowledge assistants, and agents that ingest large document corpora all fit here.
Structured stores fit when
The agent needs to store and retrieve well-defined facts with clean semantics: preferences, status flags, named entities, counters, configuration. The key-value shape of the data is known at design time. Any agent that personalizes behavior based on explicit user preferences benefits from a structured store.
Combined architecture fits when
The agent handles a variety of task types, some needing exact fact lookup and some needing fuzzy historical retrieval, across many sessions with evolving user context. Gravity's expert-built recurring agents, for example, combine structured preference memory so they know how a user wants work formatted with episodic memory from prior runs so they can continue where they left off. The user describes what they need once; the agent retains what it learned without being re-briefed. That is the practical payoff of well-designed long-term memory.
Understanding how long-term memory fits into the broader agent architecture connects naturally to how agent composability works: agents that share a memory layer can hand off context to each other, making the whole system more capable than any single agent running in isolation.
Frequently Asked Questions
What is long-term memory in an AI agent?
Long-term memory in an AI agent is any mechanism that stores information outside the active context window so it can be retrieved in a future session. Unlike the context window, which clears at the end of a run, long-term memory persists: it can hold user preferences, prior conversation summaries, factual knowledge, or records of past actions. The agent loads relevant memory into context before each run so it can reason with information it did not just receive.
What is the difference between episodic and semantic memory in agents?
Episodic memory stores specific past events in the order they happened, such as a transcript of a prior session or a record that a task was completed on a certain date. Semantic memory stores general facts and knowledge independent of when they were acquired, such as a user preference or a product description. Agents often need both: episodic memory for continuity across sessions and semantic memory for stable background knowledge that does not need to be re-derived each time.
What is the most common long-term memory strategy for AI agents?
Vector retrieval is currently the most widely implemented strategy. Memories are embedded as vectors and stored in a vector database. At the start of each run, the agent queries the store with its current context and retrieves the most semantically relevant memories to inject into the active window. It handles large memory stores well and retrieves by meaning rather than exact match, making it suitable for unstructured content like conversation history or document knowledge.
What are the main failure modes of agent long-term memory?
The two most common failure modes are stale memory and polluted memory. Stale memory occurs when stored facts become outdated but the agent continues to use them, producing incorrect responses. Polluted memory occurs when low-quality or incorrect information enters the memory store and is retrieved later as if it were reliable. A third failure mode is retrieval mismatch: the right memory exists but the wrong memory is retrieved because the embedding or query did not capture the actual information need.
When should an agent use summarization versus full retrieval for long-term memory?
Summarization works best when you need continuity across a long-running conversation or task sequence and the exact wording of prior turns is not important. It compresses high-volume history into a fixed-size representation the model can always fit in context. Full retrieval, whether vector or keyword-based, works better when specific past facts, decisions, or records need to be surfaced precisely and on demand. Many agents combine both: a running summary for conversational continuity plus a retrieval store for specific knowledge lookup.